Efficient Issue Analysis: Harnessing the Power of GPT-4 and GPT-3.5 for GitHub Repository Insights
TL;DR⌗
This post showcases a creative approach to analyzing issues in the Ordinal GitHub repository by leveraging the GitHub API, GPT-3.5, and GPT-4. The author demonstrates how to obtain the necessary data using the GitHub CLI, then uses GPT-4 to generate a prompt for GPT-3.5 to analyze the repository’s issues further.
Some key takeaways from this analysis include the following:
Automating the collection and analysis of issues and pull requests can save time and effort. AI models like GPT-4 and GPT-3.5 can help generate valuable insights and overviews of the issues. This approach has certain limitations, such as model availability and token limits. However, overall, the method proves to be efficient and cost-effective. The author provides links to the source code and the raw output of the analysis, along with examples of how to filter the result using jq play. This solution offers a practical way to quickly gain an understanding of a large corpus of issues in a repository, making it easier to identify and prioritize tasks.
If you are still here, follow along.
Why⌗
The SkyLight collective is actively building on Ordinals; as part of our R&D process in creating our artworks, we contribute when we can. We are taking our first baby steps in this land towards the reference implementation, trying to understand where it is and where it goes so that we can plant the seeds of our work. When discovering a new project, the issues are great places to start leaning in, as they are an excellent and diverse source of information related to the project. So we went into the Ordinal GitHub repository to understand what @casey, Ordinals developers, and everyday folks had to say about it.
At the time of writing (2023-03-18), there are 329 issues and 46 pull requests. As lazy developers, we wanted to automate getting the issues, pull requests, and have an initial analysis. We had to make it so we could easily update the issues and re-run the analysis if needed.
Getting the data⌗
Using the GitHub CLI, we fetched ~1MB worth of data related to the Ordinal repository issues in the JSON format extracting the information we fed to our AI using the following format:
gh issue list --json number,title,body,labels,updatedAt,comments,reactionGroups -L 400 > issues.json

The how-to is pretty simple; we used the GitHub Command Line Interface (GH CLI) to get the issues and specified the flags to get the issue number, title, body, and comments,… in JSON format. The -L flag limits the number of issues to 400 items, and pv(screenshot) gets us a progress bar while we redirect the output to a file called issues.json.
Analyzing the JSON data⌗
Example issue:
{
"body": "For the very first time, it was successful to create one inscription, now transactions are not confirmed, I suspect because of the small fee rate\r\n\r\n<img width=\"557\" alt=\"Снимок экрана 2023-03-11 в 21 30 29\" src=\"https://user-images.githubusercontent.com/53757772/224508408-186dad47-3935-4ad7-8032-5985409a87ff.png\">\r\n\r\n<img width=\"804\" alt=\"Снимок экрана 2023-03-11 в 21 35 40\" src=\"https://user-images.githubusercontent.com/53757772/224508424-16d5f897-0e83-4a04-8c32-73930e2527fe.png\">\r\n\r\nThe balance is completely debited\r\n\r\n<img width=\"563\" alt=\"Снимок экрана 2023-03-11 в 21 36 35\" src=\"https://user-images.githubusercontent.com/53757772/224508755-b202f4e0-dd2e-40cc-bea2-cdd10522bbe8.png\">\r\n\r\n<img width=\"570\" alt=\"Снимок экрана 2023-03-11 в 21 37 04\" src=\"https://user-images.githubusercontent.com/53757772/224508790-e461a21c-8f2e-4a51-962f-cf6171d4b56e.png\">\r\n\r\nhttps://mempool.space/tx/b8d7cd6ba8e2c3387d6c1dfd33ef542ed82aa36425a9a7c2f903a803aaca7015\r\n\r\n\r\n\r\n\r\n\r\nHelp me )",
"comments": [
{
"id": "IC_kwDOGhOAhc5XuYTN",
"author": {
"login": "ysw1011"
},
"authorAssociation": "NONE",
"body": "你需要设置fee:./ord --wallet tord wallet inscribe 1.html --fee-rate 6,但是你没有,所以你只能等,有一个清除本地内存池交易的bitcoin cli命令,但是我不建议你用,因为会把你钱包里数据给搞丢。所以你只能等。或者创建一个新钱包,把当前钱包余额转过去 同来产生新的UTXO",
"createdAt": "2023-03-16T11:26:11Z",
"includesCreatedEdit": false,
"isMinimized": false,
"minimizedReason": "",
"reactionGroups": [{
"content": "THUMBS_UP",
"users": {
"totalCount": 1
}}],
"url": "https://github.com/casey/ord/issues/1917#issuecomment-1471775949",
"viewerDidAuthor": false
}
],
"labels": [],
"number": 1917,
"title": "Transactions are not confirmed",
"updatedAt": "2023-03-16T11:26:11Z"
},
The above JSON data explicit long strings of text containing the issue’s body, comments, and reaction 👍. It is a good issue as it showcases multiple difficulties, contains various languages, and the title needs to be more explicit about the problem, which could be a challenge for the reviewer at first glance. More defined guidelines and issues templating could help make a more straightforward pathway for users to interact with the project.
AI for the rescue⌗
After learning much about prompt engineering over the last months, we wrote the prompt to generate the overview analysis. But after fiddling with a few prompt(s) for a while, we were not able to get a decent result in the JSON output formatting by GPT-3.5; sentiment and labeling were working fine, though.
Instead, we used GPT-4 to generate the prompt to be used by GPT-3.5 to produce the analysis, as, unfortunately, GPT-4 is yet to be available over the API.
Who knows better to talk to a robot than another robot?
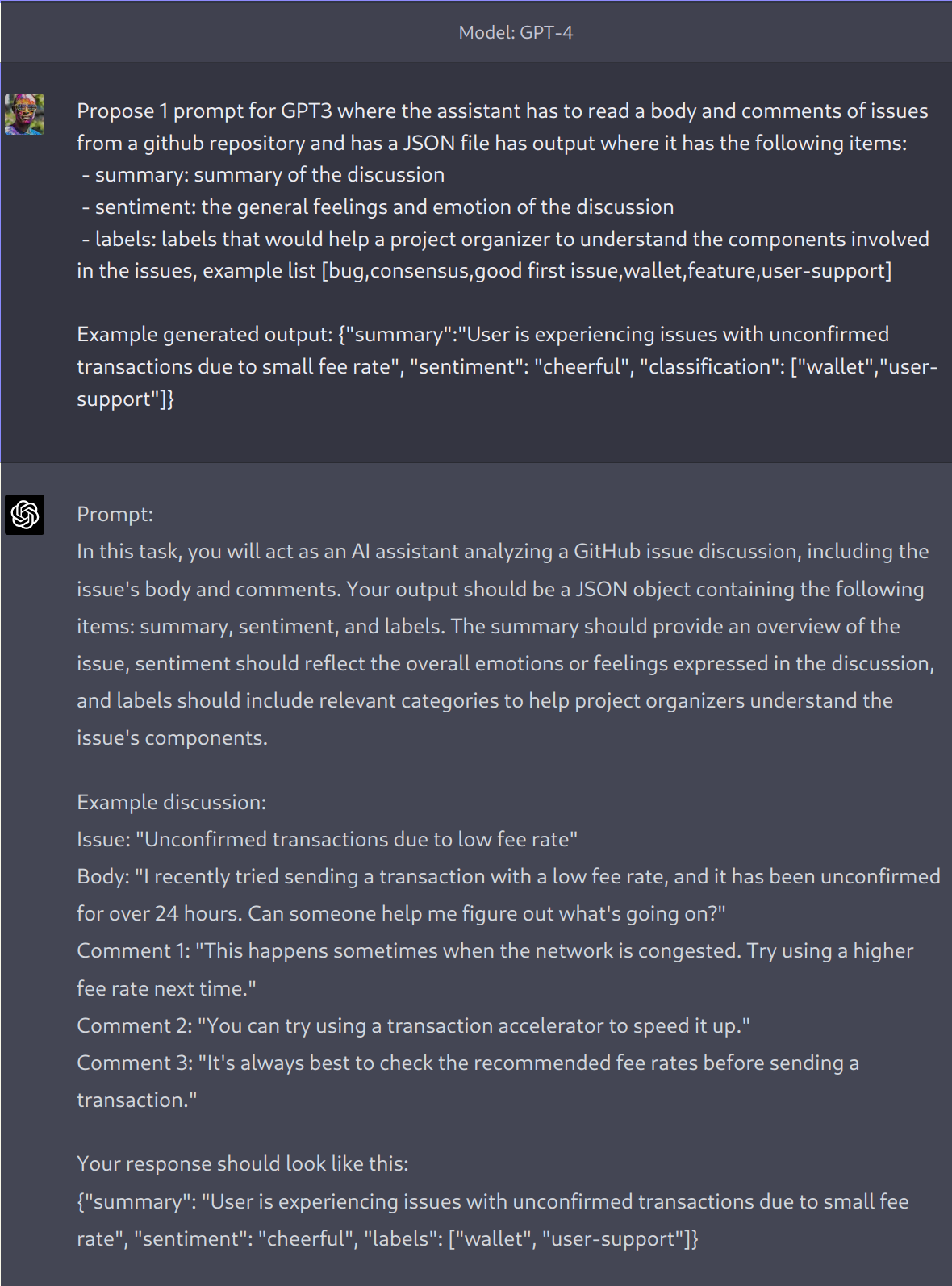
The above ChatGPT-GPT-4 conversation showcases the ask and the returned prompt proposed as input for GPT-3.5.
It gives a prompt that’s quite effective at generating usable JSON outputs.
With a few logic rules and simple use of the OpenAI python package.

We generated an overview of the issues with the title rewritten to embed comments and other pieces of information.
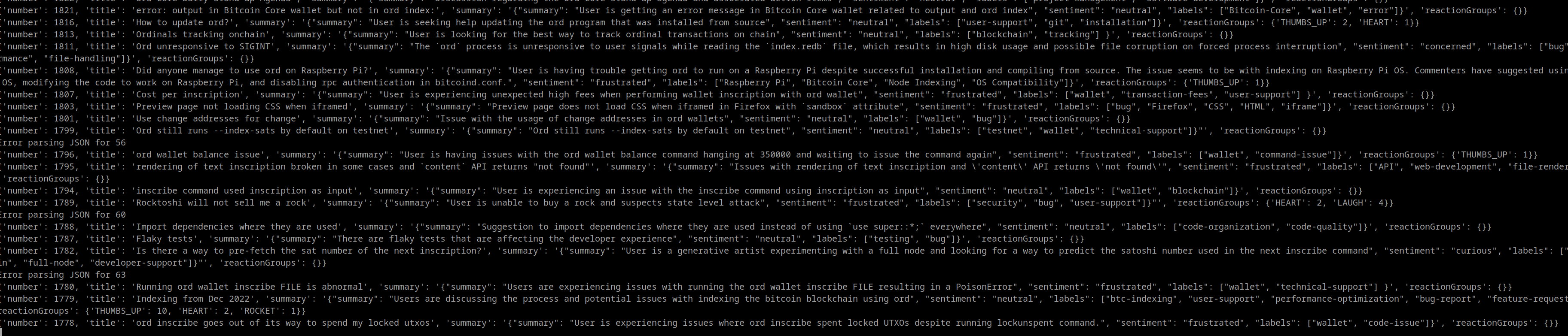
And even get some insights about which issues are hot topics.

And give a clearer short overview of the above issue.
{
"number": 1917,
"title": "Transactions are not confirmed",
"summary": "{\"summary\": \"User is experiencing issues with unconfirmed transactions due to small fee rate\", \"sentiment\": \"frustrated\", \"labels\": [\"wallet\", \"user-support\", \"transaction\"]}
The user is frustrated because their transactions are not confirmed due to a small fee rate. They have included screenshots of their balance being debited without confirmation. The comment suggests setting the fee rate and waiting for confirmation, but the user is still looking for assistance. Relevant labels would be wallet, user-support, and transaction.",
"reactionGroups": {}
}
Conclusion⌗
It’s a simple tool to help get an overview of the issues in a repository. It helps to get in the know before diving into the details, but there is some limitation to this simple example:
- The limitation encountered was the model, the only one available is GPT-3.5 which is the legacy one.
- The number of tokens you can feed the model; even with a larger model, there is a limitation. Therefore a compression on the body and comments could be applied when the number of tokens fed is close to the model limitation or some chunking.
- The prompt could be better, sometimes, it does not generate a valid JSON output, and labeling is too diverse, but it’s a good start; the required features are present.
Was it worth it? Yes, discovering a project is time-consuming and not very productive regarding deliverables. It took ~6 hours to get a deliverable (classification) and the software to produce it (another deliverable). It gave us a quick overview of a large corpus of various issues in the repository. And the OPEX development cost was almost zero.

Links⌗
- Source code
- Raw output of the analysis, you can use jq play to play with filtering to explore the data or your favorite JSON editor.